星佳数字生态系统 V1.5
星佳数字生态系统 (Project Xingjia Digital Ecosystem) \"将一生思考的数据资产,铸造成永生陪伴的智能体。\" 本项目旨在将星佳过去五年在全网沉淀的 2600+ 篇高质量文章资产,转化为一个融合了记忆检索 (RAG)、大模型极高推演能力 (Google Vertex A
星佳数字生态系统 (Project Xingjia Digital Ecosystem)
"将一生思考的数据资产,铸造成永生陪伴的智能体。"
本项目旨在将星佳过去五年在全网沉淀的 2600+ 篇高质量文章资产,转化为一个融合了记忆检索 (RAG)、大模型极高推演能力 (Google Vertex AI)、多模态生成以及网络自动化的全能数字分身系统。
- * *
📖 第一部分:产品使用说明书 (User Manual)
0\. 核心模块总览
目前,本系统最核心的前端交互入口是全功能 Web 中控台,它包含了三大主力功能:
- 🧠 灵魂导师 (对话交互):可以像心理医生或老朋友一样,基于你的历史文章对你的困惑进行超深度解答,并支持语音播放。
- ✍️ 替身写作 (AI Writer):输入一句灵感,系统自动调取你在类似话题下的文风与金句,代笔生成公众号文章初稿。
- 🤔 思想图谱 (Knowledge Graph):随机漫步并抽象出你五年来最核心的思想脉络网。

🐦 推特分发机 (Twitter Agent):
半自动防封版,从记忆切片中随机打捞商业洞察碰撞灵感,一键生成极具网感的双语推文,并自动打包高级生图 Prompt。
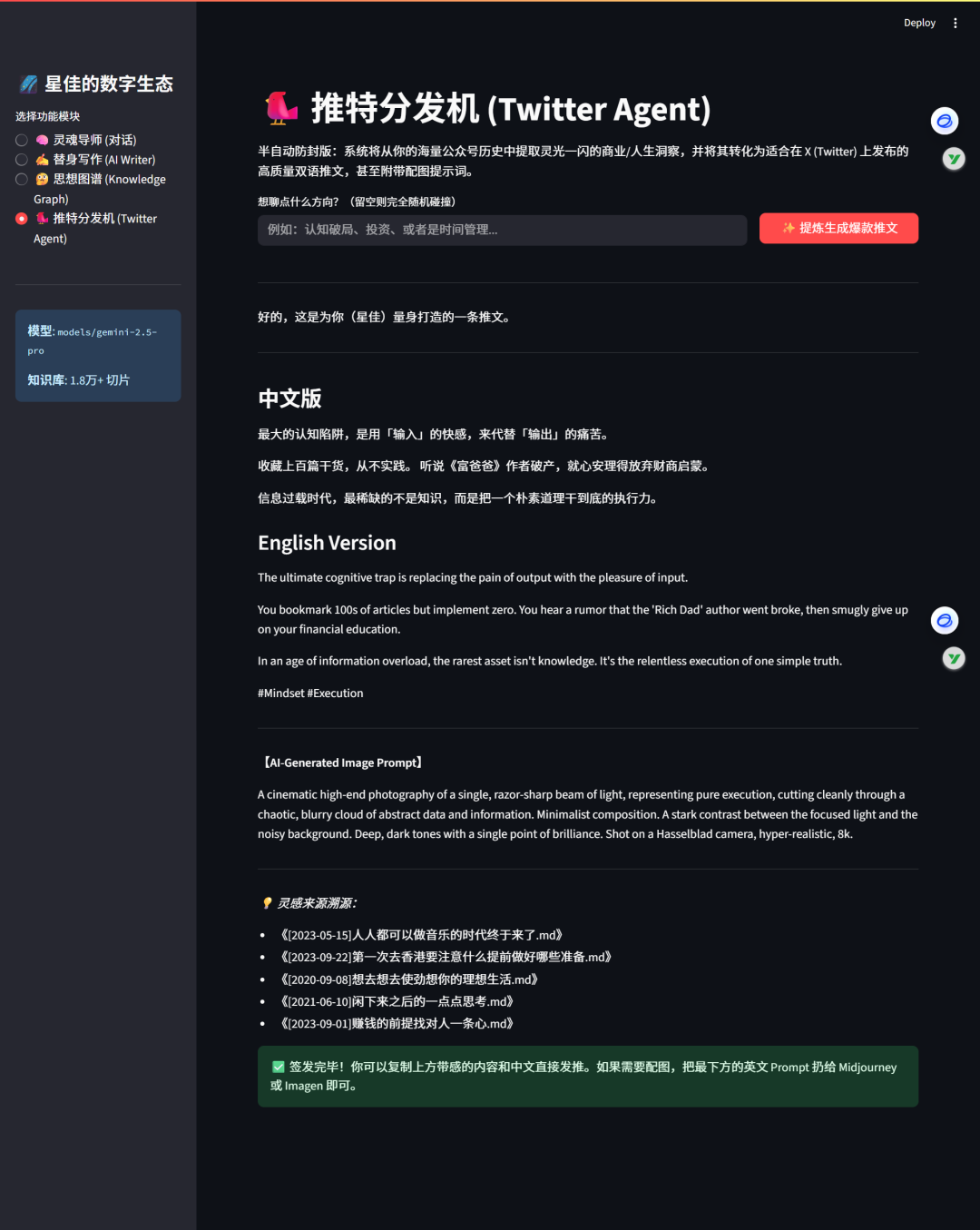
1\. 快速启动 (Quick Start)
本系统设计为高度私有化的本地/局域网服务运行。
- 启动服务:在项目根目录 (`d:\GPT\AI-demo`) 下打开终端命令行,输入以下命令即可启动 Web 服务:
streamlit run web_ui.py
*
*
*
- ounter(line
- 访问面板:启动成功后,在浏览器地址栏输入 http://localhost:8501 即可进入。
- 安全口令:为防止知识库资产泄露,进入界面需输入默认访问口令 `xingjia2026`。
2\. 使用技巧与最佳实践
- 如何让导师更懂你? 提问时尽量给出具体的场景(例如:“我最近想投资一个餐饮品牌,但是合伙人都太激进,你怎么看?”),而不是抛出一个空泛的词汇。导师会精准捕捉你的痛点,并化用你曾经的文章进行劝勉。
- 如何开启声音? 在左侧边栏勾选“开启语音播报”,当你用类似唠嗑的语气提问时,导师也会以精简、口语化的声音来治愈你。
- * *
🛠 第二部分:二次开发与维护指南 (Developer Guide)
1\. 系统底层架构揭秘 (Architecture)
整个系统是一套经典的本地私有大模型架构变种:
- 知识基座 (Knowledge Base):使用了轻量级的本地 `ChromaDB`,存放着近 2 万条由你的长文切分而来的知识切片向量化数据(采用顶级模型 `text-embedding-004`)。
- 推理引擎 (Reasoning Engine):完全由 Google Cloud 的 `Vertex AI (Gemini 1.5/2.0 系列)` 驱动,通过安全的本地凭证(gcloud CLI)鉴权,零风险,零 API Key 泄露。
- 表现层 (Presentation Layer):利用 `Streamlit` 极速构建 Web 端,以及利用 `python-pptx` 构建自动化 PPT 分析能力。
2\. 核心文件导航 (Code Structure)
开发人员主要关注以下核心组件:
- `web_ui.py`:当前最核心的 Web 服务端入口。包含了所有 UI 的渲染、与知识库的交互、Prompt 组装和 TTS 的调用。
- `rag_ingest.py` (即将迎变):知识打入工具。用于扫描你的 Markdown 文章库,调用大模型接口切片,写入本地 `chroma_db` 文件夹。
- `ai_mentor.py` & `voice_mentor.py`:旧版的命令行与文字测试代码实验场,目前其成熟逻辑已被收束至 `web_ui.py` 中。
- `feishu_bot.py`:主动出击兵器。可每天爬取各种新闻 RSS,让 AI 总结并推报到飞书。
- **`analyze_photos*.py` 系列**:AI 视觉能力演示端。可针对你的本地相册让 Gemini 直接分析总结(如之前的佛教图片分析与自动 PPT)。
3\. 环境与依赖部署 (Dependencies)
如需换一台新电脑部署,请直接执行:
ounter(line
_备注:你需要提前配置好 Google Cloud CLI 并运行 `gcloud auth application-default login` 完成项目鉴权。_
- * *
🚀 第三部分:下一步演进蓝图 (Roadmap)
里程碑更新 (2026-02-21): 我们惊喜地发现,最初规划的 阶段一(大脑增量摄入与记忆赋予) 以及 阶段二(飞书生态无缝对话与全自动多模态裂变防封排雷) 实际上已经由 `rag_ingest.py` (拥有完整 MD5 校验文件去重机制)、`web_ui.py` (包含上下文 Chat History 记忆流) 以及极其强大的 `feishu_bot.py` (接入了飞书事件引擎并集成 Imagen 3 全自动小红书/TikTok文案图片生成能力) 全部实现完毕!
目前系统已经是一个完整可用的“完全体”。
接下来的真正演进蓝图(V2.0 终极进化阶段)如下:
阶段 3:服务端的终极容器化与服务化 (DevOps)
- \[ \] 私有 Docker 镜像:编写 `Dockerfile` 实现“代码+本地轻量化万段知识切割库”合二为一。无论将其部署在本地 NAS 群晖还是海外的云端服务器,均能一条命令:跑!
- \[ \] 面向客户的鉴权沙箱:为“星佳流咨询客户”开放独立的网页端有限查阅权限,打造知识付费的终极交付物。
- \[ \] Cloud Run 一键上云:利用 Google Cloud Serverless,实现 0 并发 0 收费,抗高并发请求的究极部署。
阶段 4:主动行为智能体 (Proactive Agent)
- \[ \] 全自动推特/邮件分发机:赋予 `feishu_bot.py` 定时休眠与唤醒的能力,让其无需等待指令,结合每天的新闻摘要主动起草高质量的英文 Twitter 科技评论,甚至全自动发推。
- \[ \] 真实 1:1 声音克隆对讲:将 Web 端的基础文字转语音打通开源或商用的深度声音克隆接口,未来可以直接通过飞书语音条发一段感悟给客户(全部是由 AI 用你的声音生成的)。
- * *
_文档更新日期:2026-02-21_
下一步规划。
如果你也有大量的原创内容想接入这个数字生态系统,可以聊聊看,你的新需求,等时机成熟我会考虑开源这套系统到github,大家可以自己部署了,没必要重复造轮子!
<!-- growth-cta -->
如果这篇文章对你有启发,可以继续关注公众号「星佳是个小人物」,也可以加微信 xingjia9527 交流。 我现在主要围绕家庭决策、香港身份、AI 个人知识库和普通人赚美金这些主题,提供付费咨询、线上交流和线下培训。